你的位置:国产自拍偷拍在线视频 > 三级片电影 > 村上里沙快播 携程基于Kafka的数据校验代理在FinOps规模的应用


作家简介村上里沙快播
懿涵,携程HybridCloud团队云原生研发工程师,顾惜云原生、IaC规模。
为了灵验照拂云本钱,基于携程羼杂多云和自建PaaS为主的近况,羼杂云团队研发了FinOps计费系统。本文将先容计费系统基于Kafka构建的接入体系在数据质料与治理方面的挑战,并共享基于自研Kafka Gatekeeper构建度量及治理自助化自动化的现实。
一、近况与问题
1.1 近况
1.2 问题描述
1.3 治理有筹谋
二、想象与中枢终了
2.1 Kafka的相干配景常识
2.2 Kafka Gatekeeper的想象和终了
三、记忆
一、近况与问题
1.1 近况
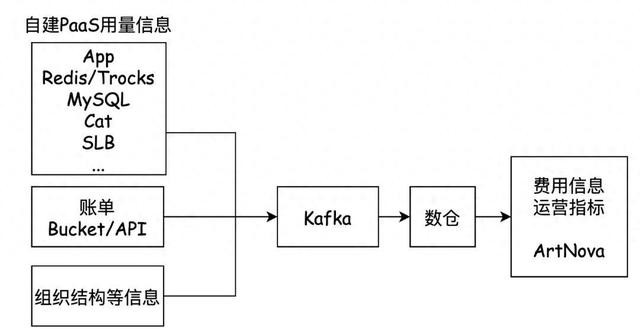
图1-1
如图1-1所示,携程当今使用了羼杂多云的模式,同期也以自建PaaS劳动为主,因此计费系统除了需要从云商获取账单等信息,还需要接入几十种自建PaaS劳动的用量信息。其主要结构如下:
1)TripCostAllocationProtocol: 为了计费接入的扩张性,计费系统想象了计费公约,兼容羼杂多云模式,维持自建及原生PaaS/SaaS劳动。
2)计费数据接入:云原生劳动结伙由计费系统处理,自建劳动由各团队按TripCostAllocationProtocol如期打点的口头,将用量信息送达到Kafka中。
3)计费处理:计费系统笔据接入的账单、用量以及劳动间的关系,进行递归结算,并将截至落到里面数仓。
1.2 问题描述
计费系统上线后,顺利为照拂层、运营以及研发等脚色提供了计费及本钱分析的智商。在数据质料上,系统在数仓截至表上创建了对应的检测规则,针对流露违犯业务逻辑的数据不错触发告警。但是,跟着系统的抓行,数据质料的问题仍然居高不下,具体阐发如下:
问题发现:
a.障翳率低:针对数据荒谬进程在一定规模内,但仍然稳健业务逻辑的问题,无法被检测到。
b.实时性差:由于检测基于截至表,告警只可针对计费截至,告警截至有滞后性。
问题定位:
a.后果低:检测是运行在计费系统里面的截至表上,需要多个数据接入方团队及计费系统设备东谈主员共同排查,细目问题发生的泉源及原因。
问题治理:
a.连累不解:由于质料检测基于截至表,但变成问题的泉源千般。无法通过对截至的检测径直将问题包摄到对应团队,问题无法得到实时的顾惜与处理。
数据质料是计费系统的生命线,原有系统在质料上的问题导致计费系统设备团队深广的时间被挥霍在对证料问题的反馈、排查与树立,无法联结元气心灵参预在产物迭代上,也无法搪塞更多劳动的接入。
1.3 治理有筹谋
针对以上问题,咱们决定从头构建数据质料治理的智商。地方如下:
问题发现
a.全问题障翳:从数据泉源启航,扫数不稳健校验规则的运转数据齐不错被发现。
b.实时性提高:数据相当在进入计费链路之前就不错被发现,而非通过计费截至告警。
问题定位:
a.提高后果:无需多方团队勾通排查,自动拿获问题泉源及问题发生的原因。
问题治理:
a.连累明确:问题产生确当下就示知相干连累东谈主,明确问题治理的对应团队。
通过分析数据质料的案例,发现绝大部分数据质料的问题来自于几十个自建劳动数据接入方。笔据以上地方的梳理的问题的分析,咱们决定引入Kafka Gatekeeper组件,重心治理自建劳动接入的质料问题,如图1-2所示。该组件提供以下智商:
1)校验前置:打点数据在进入计费逻辑前,先进行规则校验,保证问题发现实时性。
2)规则可建设:校验规则可随时建设、随时更新,保证规则检测的全障翳。
3)自助排查:提供自助查询看板,包括数据荒谬条数,问题发生原因等信息,研发可自助查询对应团队的相干信息,提高问题定位后果。
4)自动告警:检测发现不对规数据(如字段缺失、数据类型荒谬等)时,向数据来源的团队发送告警,明确问题治理连累。
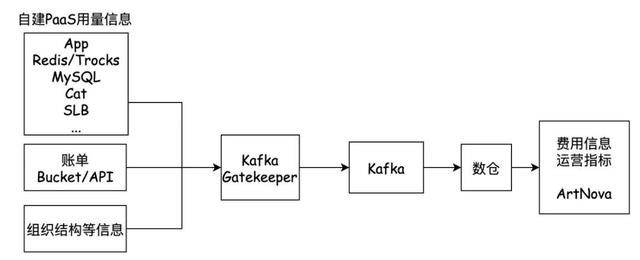
图1-2
二、想象与中枢终了
2.1 Kafka的相干配景常识
为了终了Kafka代理劳动的数据校验功能,需要治理以下两个问题:
1)怎样笔据Kafka公约对音书进行解码。
2)若那边理Kafka客户端,劳动端和代理之间的相接关系。
2.1.1 通信公约
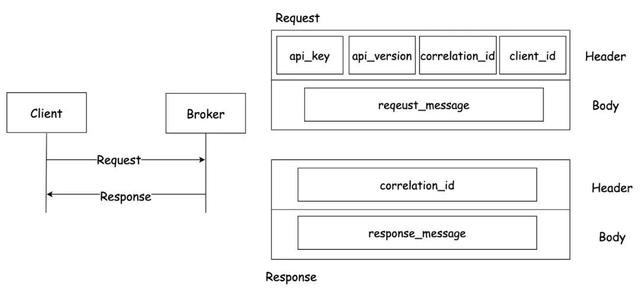
图2-1
如图2-1所示,Kafka苦求只可由Client主动发到Broker,Broker针对每个苦求修起反馈给Client。
Kafka使用基于TCP的自界说二进制公约。它界说了客户端和劳动器之间的音书行动、音书传递口头和处理逻辑。扫数音书齐是通过长度来分隔,况且由基本类型构成。苦求由苦求类型(ApiKey),版块号(ApiVersion),相干性艳丽(CorrelationId),客户端艳丽(ClientId)和苦求音书(RequestMessage)构成。反馈由相干性艳丽(CorrelationId)和反馈音书构成(ResponseMessage)构成。
ApiKey用于说明Request的类型,以通过不同类型的数据行动剖析苦求。Request和Response通过CorrleationId来一一双应。
由于发送出产音书,仅包含两种API--元数据(Metadata)和出产(Produce),本文仅顾惜这两种API的请乞降反馈,公约行动见图2-2。
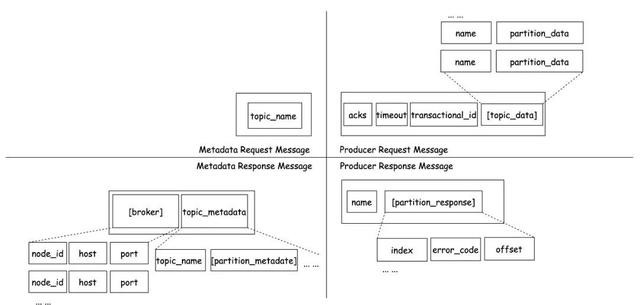
图2-2
Metadata是用于获取元数据的API。元数据苦求在捎带topic_name时会复返topic相干的数据,若是为空则复返扫数主题。元数据反馈复返的数据包括一串broker的数据信息,以及topic名、分区信息等。图中不详部安分容,仅展示和本文相干的部分。
Produce是用于将音书集发送到劳动器的API。出产苦求将捎带地方topic,以及分区信息,其平分区信息中包含所要发送的具体音通告录聚合。出产反馈复返的数据包括具体的苦求截至。图中不详部安分容,仅展示和本文相干的部分。
通过了解以上两种API的行动,不错基于公约行动进行解码。
2.1.2 交互经由
处理相接关系,还需要了解Metadata、Produce公约的交互经由。
元数据苦求不错发往淘气broker。Kafka集群会提供Bootstrap地址,由此地址负载平衡到某一劳动器并复返。客户端提供一组topic,劳动端复返元数据反馈,包含扫数的broker信息和相干的topic信息。broker信息中包括节点的IP地址,即客户端真确发送出产信息的劳动器地址。
出产苦求将会发送到元数据苦求中复返的某一劳动器上,劳动器端将会复返苦求截至。
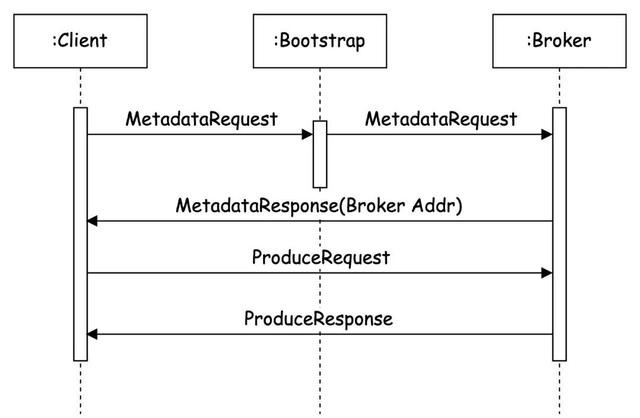
图2-3
如图2-3所示,将集群简化为一个Broker,Produce的具体经由:
1)Client向Bootstrap地址发送元数据苦求,查询集群现时Broker列表。
2)Bootstrap的确反馈的Server其实是(某一个)Broker,Broker复返了扫数的信息包含在元数据反馈中。
3)Client向的确的Broker地址发送出产苦求。
4)Broker处理苦求,并修起反馈。
通过了解Kafka出产的基本经由,不错终了代理,给与并处理其中的相接关系。
2.2 Kafka Gatekeeper的想象和终了
Gatekeeper行动Kafka客户端和劳动端之间的代理,接受客户端的苦求关于指定本体作念数据校验,并转发给劳动器,同期将劳动器的反馈复返给客户端。
关于客户端来说,仅需要将本来建设的Boostrap地址改成Gatekeeper的地址。
关于Gatekeeper来说,需要作念到:
1)想象解码器妥协码有筹谋:解码Kafka音书,从而进一步进行处理。
2)想象校验器和校验规则:进行数据校验,提高数据质料。
3)贵重Boostrap地址和Gatekeeper地址之间的映射关系:处理客户、Gatekeeper、劳动间的相接。
Gatekeeper想象架构如图2-4所示。
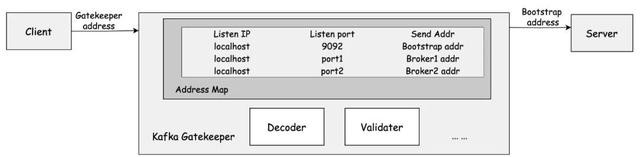
图2-4
解码器用于在处理苦求时,笔据Kafka公约和自界说的解码有筹谋解码。当剖析元数据苦求时,笔据自界说的映射关系修改复返的元数据反馈。
校验器当剖析的是出产苦求时,会笔据自界说的校验规则进行校验。
映射关系被贵重在Gatekeeper中处理相接关系。
Gatekeeper贵重的映射关系中,由于Kafka的默许端标语是9092,"Gatekeeper的IP地址+9092端口"的相接将与"Bootstrap的IP+9092端口"作念映射。"Gatekeeper的IP+port1"的相接将与"Broker1的IP+9092端口"作念映射,"Gatekeeper的IP+port2"的相接将与"Broker2的IP+9092端口"作念映射,以此类推。Gatekeeper就不错笔据这个映射关系,处理来自客户的苦求,发送给相应劳动端,并一样处理来自劳动端的反馈。
一言以蔽之,Kafka Gatekeeper监听了客户端发来的苦求,笔据建设转发给劳动端,一方面剖析了客户端的出产信息作念数据校验,另一方面修改了劳动端的元数据反馈信息给用户,以保证用户的出产信息老是通过Gatekeeper进行转发。
2.2.1 欺诈通信公约进行剖析
通过前文可知,每个请乞降反馈齐有固定行动的header和具体的苦求包。而由于Kafka每一种公约也齐有固定的行动,Kafka公约中可使用的数据类型是固定的,且是按律例存储的。
因此,只需给每种数据类型终了一个特定的编解码有筹谋,并通过header中捎带的ApiKey和ApiVersion,细目某一个解码行动,就不错笔据收到的包序列化数据。
总而言之,Gatekeeper的解码器需要完成两个任务:终了不同数据类型的序列化功能,以及笔据版块细目公约行动。
以version-1的出产音书为例:
从编解码角度来说,每个公约包齐是由4字节的size起首,背面再跟相应字节的苦求包或反馈包。解码器最初和会过序列化功能剖析了这个4字节的size,筹谋出苦求包的大小。
一样的,解码器筹谋出2个字节的ApiKey和ApiVersion(和本文无关的其他字段暂时略过)。解码器筹谋诞出产苦求的的ApiKey为0,ApiVersion为1。这么解码器的说明版块功能就能细目一个公约行动,再笔据这个行动的数据类型去一一作念剖析。
至此,Gatekeeper不错就笔据不同类型,不同版块的的客户端苦求,完成剖析。笔据即时的解码本体,针对需要再进一步处理,不错保证问题发现的实时性。
2.2.2 欺诈交互经由进行相接处理
Gatekeeper的责任旨趣是在腹地机器上大开tcp套接字,并在使用套接字时,代理相接到相干的Kafka劳动,它将腹地端口与的确的劳动地址进行映射。
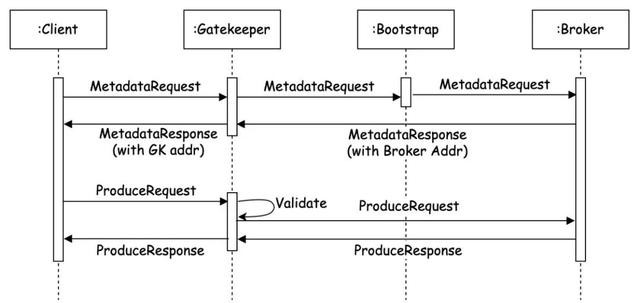
图2-5
如图2-5所示,用户加入Gatekeeper劳动后,Produce的具体经由:
1)当客户端发起第一条元数据苦求时,发送地址是Gatekeeper地址,苦求将会被Gatekeeper监听到。
2)Gatekeeper发起一条到劳动端的相接,把监听到的相接发送给Boostrap地址,同期存储一份Boostrap地址和腹地地址的映射。
3)元数据反馈会复返一串Broker的相干信息,Gatekeeper经受到相干信息后,会剖析本体将Metadata数据华夏本的节点IP信息,替换成Gatekeeper的地址。
4)当客户端发送Produce苦求时,通过经受到反馈里的地址和Gatekeeper建立相接的。
总而言之,客户端的Produce经由齐经过Gatekeeper,Gatekeeper不错对扫数的Kafka音书进行校验。保证打点数据进入计费链条前先进入校验逻辑,终了校验检测全障翳。
2.2.3 可建设化校验与自助相当定位
Gatekeeper的地方,是提供一个针对Kafka音书的前置数据校验代理,治理接入劳动的数据质料问题。从数据泉源滥觞,建设校验规则检讨每个topic的数据是否合规,定位相当数据来源,向相干团队告警,并提供自助排检察板。
提供可自界说建设的校验规则,不错随时更新、矫正,况且提供笔据解码本体明确连累东谈主的功能。Gatekeeper的校验器会笔据建设的规则,对比分析解码本体作念校验。提供包括判断字段类型、检讨字段缺失、以及稳健CEL语法的校验规则等功能。
以如下schema为例,TripCostAllocationProtocol商定某topic必须包括,不为空的字符串Name字段,和可选且大于零的整形Timestamp字段。
schema{Name: "", //required TimeStamp: 0, //optional ...}
相应的,Gatekeeper建设如下,针对该topic的TripCostAllocationProtocol商定,建设校验规则。在数据流经代理时,笔据规则全面检测。
"Topics": [ {"Name": "fake.topic","Owner": ["Key":"Name" ],"SchemaRules": [ {"Name": "Name","Type": "string","Optional": false }, {"Name": "Timestamp","Type": int,"Optional": true"Rule": "TimeStamp>0" } ] } ]
以Timestamp字段造孽零值为例,当Gatekeeper教练发现,此条音书不稳健建设的规则 "Timestamp>0",会笔据建设的Owner,锁定数据来源“Service A”并告警反馈给该团队,明确问题连累。
此外,Gatekeeper也提供了自动告警功能和自助查询功能。如图2-6所示,处理用户出产数据的经由以实线透露,是“用户-代理-劳动”的线性经由,全障翳所罕有据一进行校验。同期Gatekeeper向日记系统和监控系统离别发送了校验失败见解和详备信息日记。
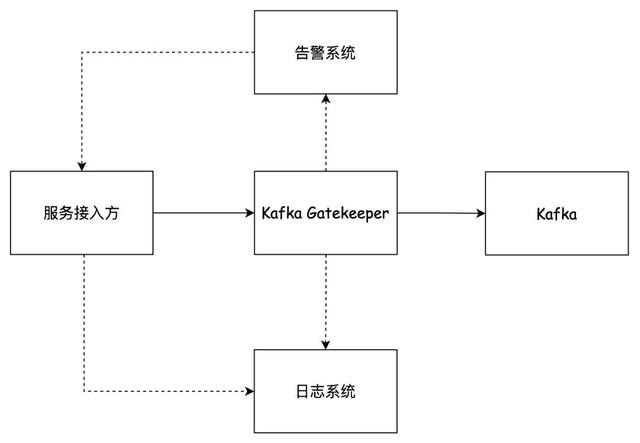
图2-6
校验到不对规数据时,用户经受监控告警,通过监控系统不错检察包括数据荒谬条数,校验通过率等本体。
以上述荒谬为例,自建PaaS劳动Service A收到fake.topic中出产了校验不对法数据的告警。Service A的研发团队通过检讨告警系统检讨告警信息。研发团队不错跳转到对应的日记系统,以检讨荒谬日记以及校验欠亨过字段的规则,笔据荒谬日记自助树立数据。
通过自动告警,提高了问题的定位后果,明确了问题连累方。通过提供自助查询看板,可视化展示校验截至和相当来源,便捷研发团队自助树立数据,闭环治理经由。
2.2.4 高可用部署
笔据携程的可用性最好现实,终了跨AZ高可用和数据校验就近处理。如图2-7所示,劳动给用户提供结伙进口,并在AZ里面署多个实例提供劳动。
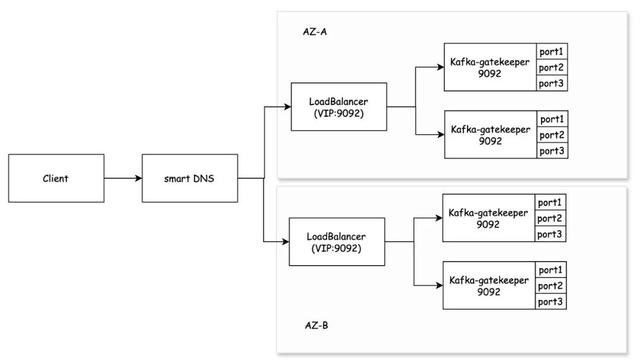
图2-7
如图2-8所示,(1) 是原始的Kafka客户端和劳动端交互过程暗示图,(2) 是单AZ内,增多了Kafka Gatekeeper作念代理后的交互过程暗示。
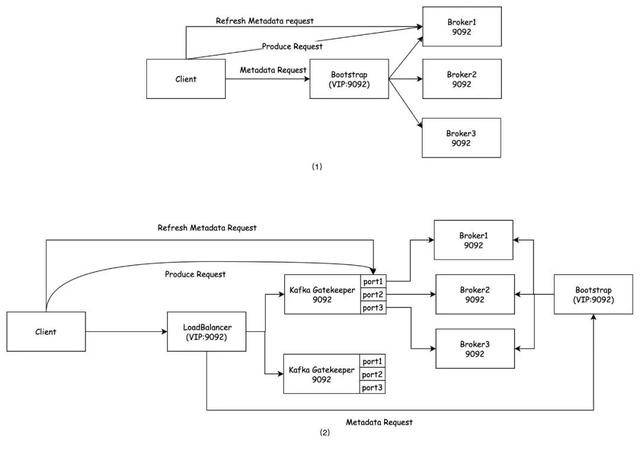
图2-8
此前,Gatekeeper的地址需要承担的三项连累--监听,播送和提供进口:
1)监听来自客户的元数据和出产苦求。
2)复返元数据反馈时,提供给用户新的出产苦求发送的播送地址。
3)提供客户端,用于替换本来Bootstrap的进口地址。
在高可用的部署架构下,Gatekeeper的地址不再承担提供进口的连累,客户端使用总的进口地址代替本来需要建设的Bootstrap地址。
2.2.5 本事挑战
在某次重启劳动后,尽管劳动看起来平时运行,况且新增接入的客户端也稳健预期,但部分已接入的Java客户端老是相接失败,直到客户端自行重启劳动。经过测试发现,这种情况与客户端刷新元数据的行动相干。
人体艺术照Kafka出产苦求不能达时,客户端会作念一次元数据的刷新。反馈这个刷新元数据苦求的Broker会笔据注册中心复返现时可达的Broker节点列表。在第一次发送元数据苦求时,客户详察接的是Bootstrap地址(加入Gatekeeper的经由中,相接的是Gatekeeper的IP地址)。然则,在刷新元数据时,客户端的行动有一些区别。
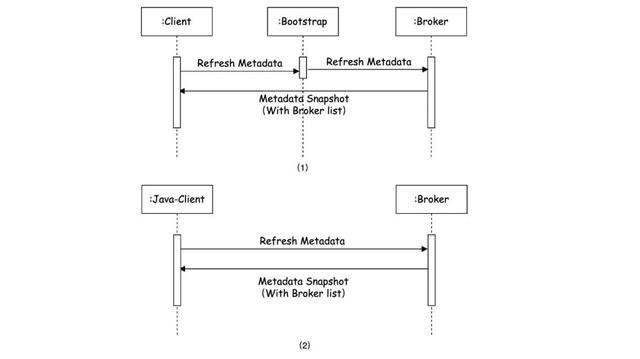
图2-9
如图2-9(1)所示,测试时使用的客户端刷新MetaData的苦求,和运转发送元数据苦求一样,发往Bootstrap地址。而Java客户端只好第一次启动时把元数据苦求发给Boostrap地址,如图(2)所示,Java客户端的刷新MetaData的请是径直打给具体Broker地址的。
在加入Gatekeeper劳动之后,如图2-10(1)所示,监听苦求的地址和复返的播送地址是Gatekeeper我方的IP地址,播送地址用于代替元数据反馈中的的Broker地址信息。也便是说,Java客户端在刷新元数据信息时也会将苦求发往Gatekeeper的IP地址。而由于劳动重启,Gatekeeper实例的IP地址发生了变化。因此,客户端也无法通过刷新元数据得到当今可达的劳动地址,导致相接失败。
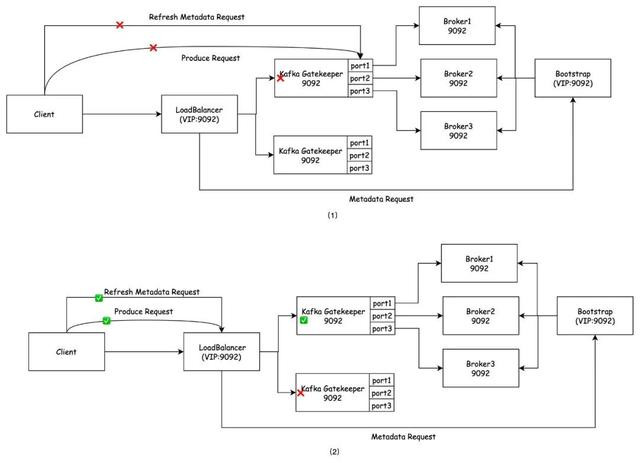
图2-10
总之,不同客户端在刷新元数据的口头上存在互异。Java客户端会缓存Gatekeeper的IP地址,当这个地址变得无效时,相接就会失败。而当客户端的相接老是发送到一个灵验的负载平衡地址,因此不会出现这么的问题。
因此,只需让客户端缓存的地址,也便是在元数据反馈中复返的地址,老是灵验的,就不错幸免以上问题。
本来Gatekeeper的IP地址承担了监听和播送两个功能,其中播送地址与Broker地址一一双应。如图2-10(2)所示,为了治理固定IP的问题,劳动使用挂载的固定负载平衡地址替换原有播送地址。同期,使用固定规模的端标语代替赶快的端标语,且LoadBalancer上与Gatekeeper上映射的端口是全齐一致的,就不错治理固定端口的问题。
这么,即使Gatekeeper不像Kafka一样使用注册中心来注册扫数可达的地址,仍然不错确保客户端恒久约略找到劳动,而不会丢失相接。
三、记忆
Gatekeeper是一个提供对Kafka数据进行校验的器具,并终了校验规则的可建设化。同期Gatekeeper还提供了可视化展示校验截至和相当来源的监控看板,并提供自助查询荒谬日记的功能。在泉源终了定位相当,保证了规则检测全障翳,并提供自动相当发现和自助相当定位劳动,从而完成了治理闭环,擢升了数据质料。
当今Gatekeeper的适用规模仅限于FinOps计费系统,但合座架构是针对Kafka音书想象的,因此它不错行动一个可复用的数据校验代理。改日村上里沙快播,Gatekeeper但愿能提供一个通用的数据系统校验处贤慧商,以治理更平庸的数据质料问题。
Powered by 国产自拍偷拍在线视频 @2013-2022 RSS地图 HTML地图
Copyright Powered by365建站 © 2013-2024